Paper-ATC'2022-GPULet
# Abstract
本文以最大化资源利用率和任务吞吐量为目标,为多模型推断的 GPU 集群实现了一个在线推断请求调度框架,在物理 GPU 与在线的请求之间设计了 GPULet Scheduler 工具来将 GPU 的计算资源分割成 GPULet,在分割计算资源时,本文综合考虑了时间、空间上的 GPU 资源,以及每次处理请求的批次大小,并且将搜索成本降低到了实际的在线系统可接受的范围。该系统在处理多 DNN 场景时能够自发调节使用的 GPU 个数以节约资源,另外,该系统额外考虑到了不同的 DNN Model 在 GPU 上的并行推断产生的冲突问题,建立了干扰预测模型。
# Introduction
CPU 上下文切换的速度是微秒级别,而 GPU 是毫秒的级别。
# Background
在 Background 章节,作者从三个维度阐述了提高 GPU 利用率的方法。
-
Batching-Aware ML Inference Serving
与预先加载好数据的模型训练相比,模型推断不能实现 GPU 资源的高利用率的原因是在在线推断场景中,推断请求是在线产生的。人为地设置 GPU 处理推断任务时的批次大小,可以提高 GPU 内核的利用率。
-
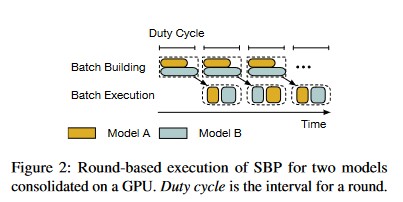
Temporal Scheduling for ML on GPUs
作者介绍了 Nexus,通过将 GPU 资源在时间上分片提供给不同批大小的模型来提高 GPU 的利用效率。
Nexus 采用 SBP 算法。
-
Spatial Sharing on GPU
作者介绍了 GSLICE,它的逻辑是根据推断结果的反馈来调整各个分区的资源占比,确定资源占比后启发式地调整批处理的大小,但 GSLICE 只针对单个 GPU。
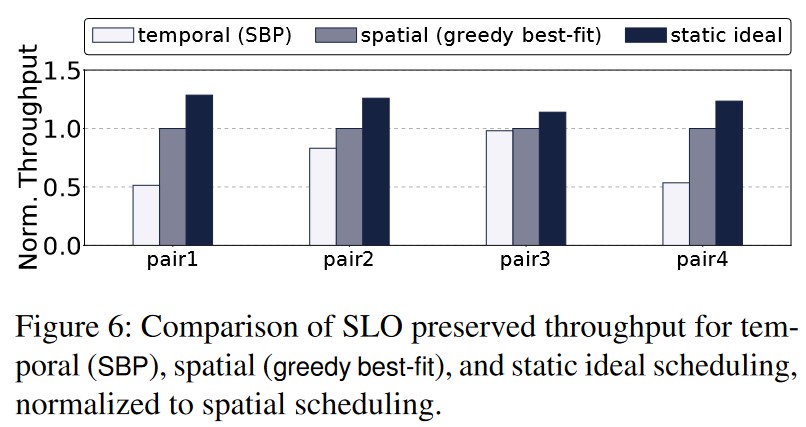
本文的目标是在空间、时间以及批次大小三维的基础分割 GPU 资源实现最大化资源利用率和最小化使用 GPU。作者在 background 章节另外提出了本文的两个 baseline,分别是时间 baseline 的 SBP 算法和空间 baseline 的 Greedy best-fit 算法。
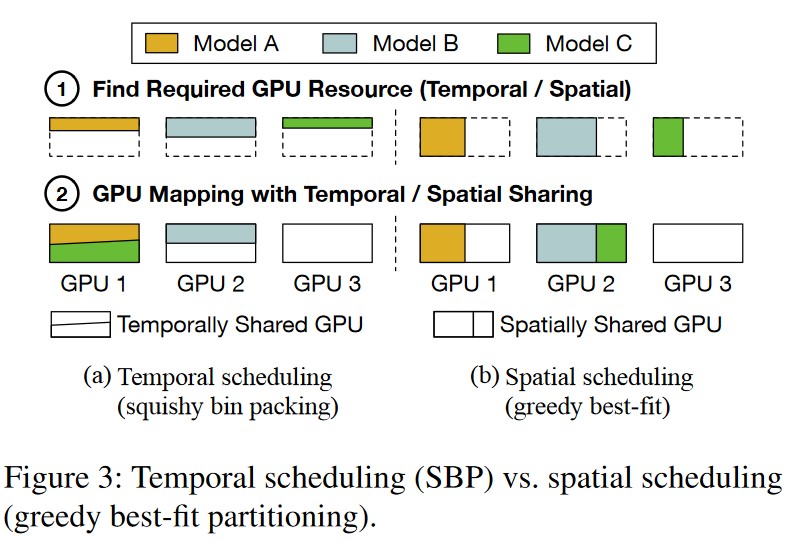
# Motivation
-
Pre-Experiment-1:推断任务的最佳批大小与 GPU 的空间分区之间存在紧密的联系。
作者选取不同的模型
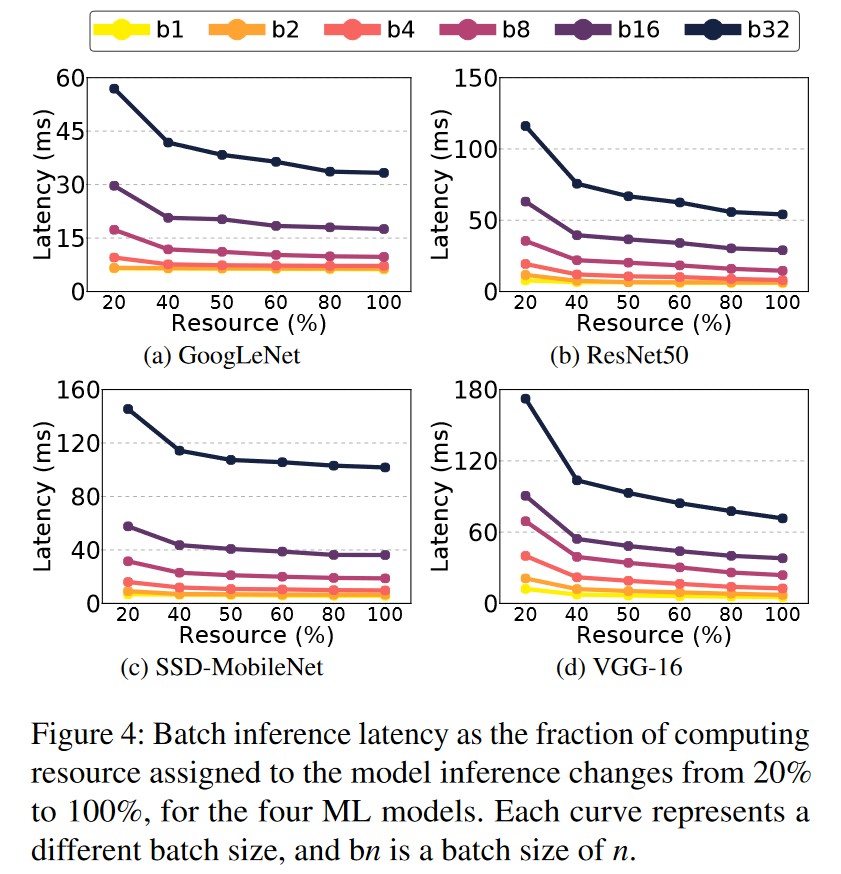
-
Pre-Experiment-2:时 / 空 / 批三维的搜索空间得到的推断任务调度最优解比时 / 批二维的搜索空间得到的推断任务调度最优解更优。
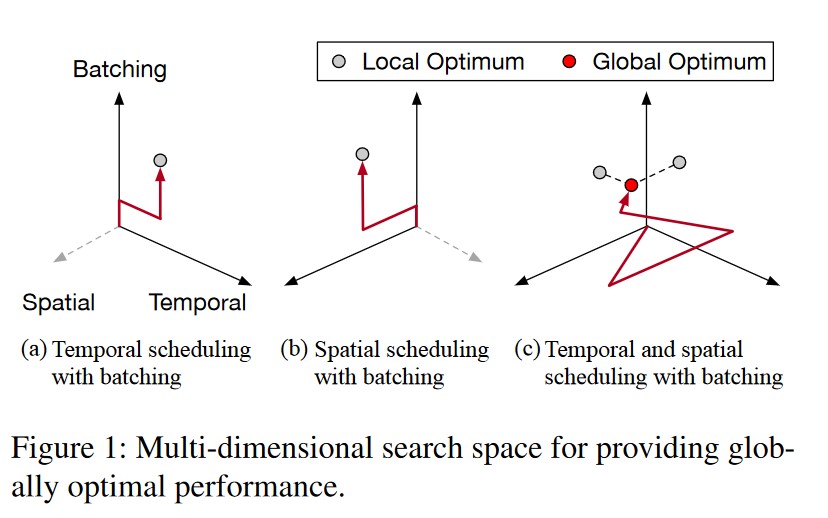
-
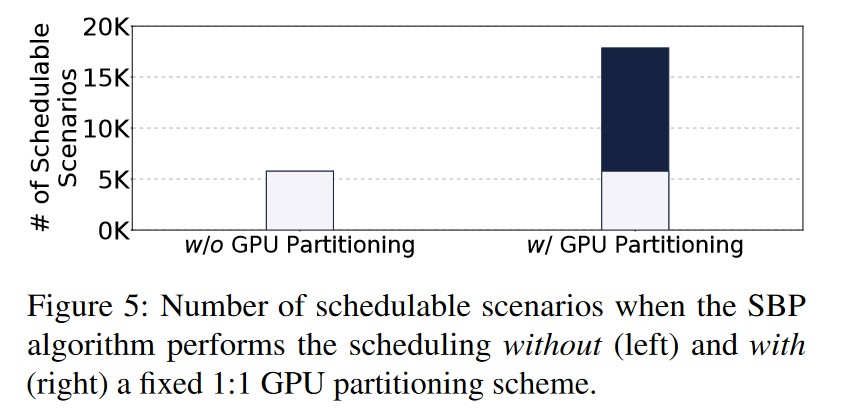
Pre-Experiment-3:在有效分割的前提下,时空 GPU 资源调度可以有效提高 GPU 的资源利用率,提高系统的吞吐量。
-
Pre-Experiment-4:不同的 Model 同时在一个 GPU 上进行推断任务时,由于存在资源争用问题,并行执行可能会存在额外的干扰开销。

# Design
-
GPULet
为了给不同的模型分配的 GPU 资源,作者引入了 Gpulet,Gpulet 是建立在物理 GPU 上的一个虚拟的 GPU,它是 GPU 在空间和时间上分配的计算资源的集成。
For each trained ML model, a minimal performance profile is collected offline.
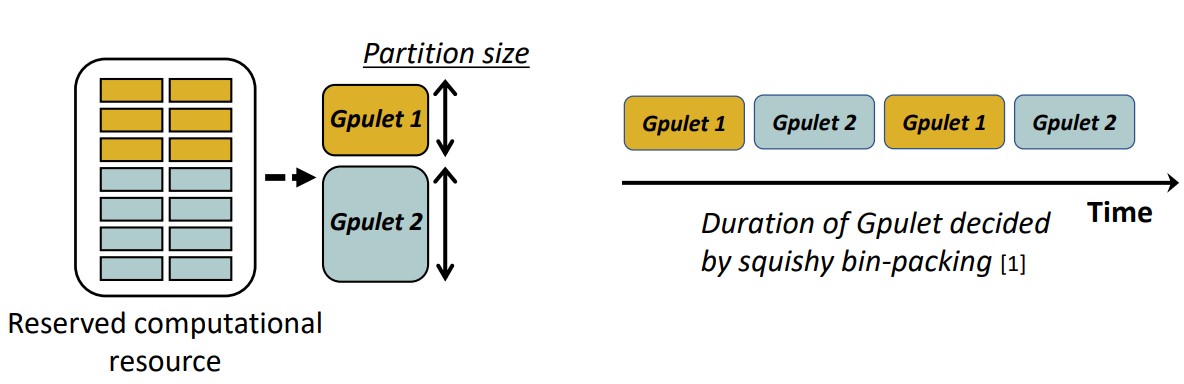
-
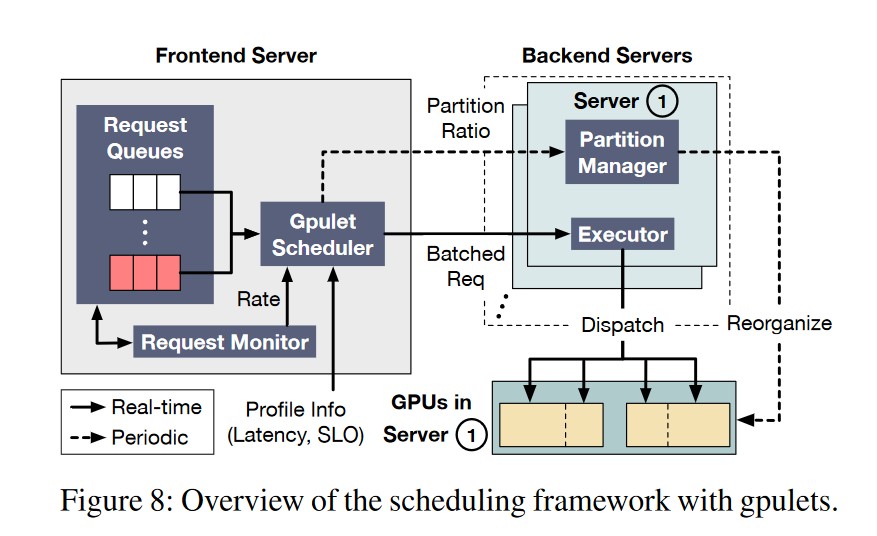
Overview
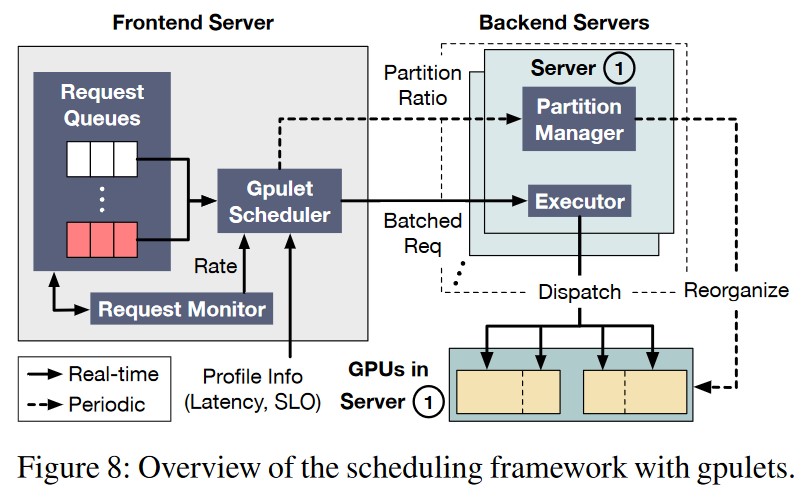
Request Monitor:监视不同 Model 的 Request 频率,作为调度器调度的参考变量之一。
**Gpulet Scheduler:** 综合配置文件中不同 Model 的时延、SLO 要求、Request 的到达频率,决定
- 该 Model 的 Request 以何种批次大小执行。
- 该 Model 的 Request 在哪块 GPU 上执行。
- 该 Model 的 Request 在 GPU 的空间分区、时间分区的资源占用情况。
**Partition Manager:** 实现 GPU 的分区,并且周期性的根据 Request 的 Rate 进行调整。
**Executor:** 实现 Scheduler 的决策,将 Request 分配到不同的 Gpulet 上执行。
-
Challenge-1: Achieve Cost-effective scheduling
本文实现的核心调度算法,目标是最大化系统的吞吐量的同时最小化资源消耗。相比二维的情况,三维显著增加了调度的搜索空间,因此作者引入了配置文件,记录了 Model 在不同的 batch size 下不同的 Gpu 空间分区的时延大小。
-
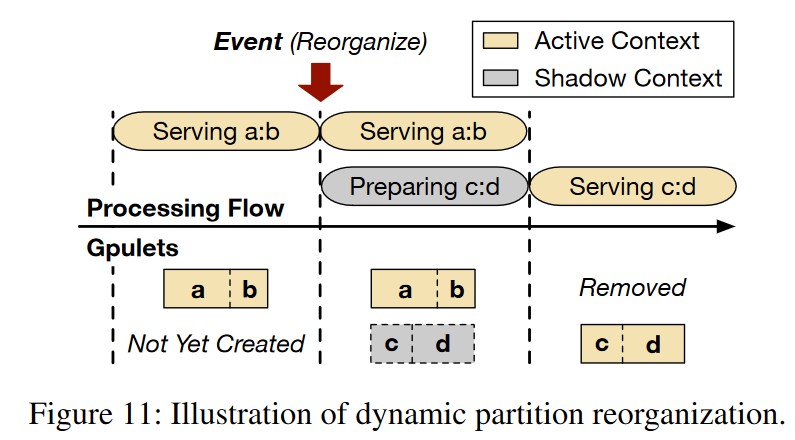
Challenge-2: Dynamic reorganization
当 Model 的 Request Rate 发生变化时,触发 GPULet 的重新调度。在 Gpu 上实现新的分区需要一定的代价开销,原文引用如下。解决的方法是周期性地
Preparing a new partition includes spawning a new process, loading kernels used by PyTorch, loading required models, and warming up.
-
Challenge-3: Interference prediction
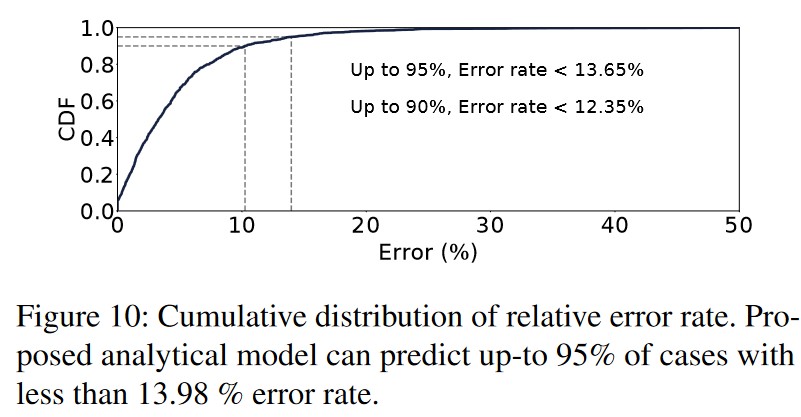
量化不同的模型在同一个物理的 GPU 上并行处理时的时延干扰损失,作者在衡量多个因素后选取了两个重要因素,通过线性回归判定 Model A 和 Model B 在同一块物理 GPU 上并行执行时的时延的额外开销,实验证明该错误率在 10% 左右。
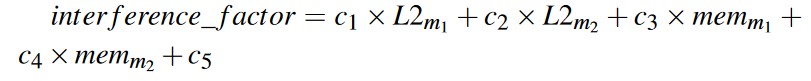
# Evaluation
# Conclusion
Paper-ATC'2022-GPULet